Job submission#
You can submit Dell Data Processing Engine batch jobs and launch Spark Connect servers from the Starburst Enterprise web UI. Batch and Spark Connect jobs can also be managed programmatically with the CLI.
Batch jobs UI#
Click Spark jobs in the Dell Data Processing Engine section of the Starburst Enterprise web UI to view and manage batch jobs and Spark Connect servers. You must have the Spark runtime UI privilege to access the Spark jobs pane.
The Batch jobs tab shows a list of jobs and information about each job:
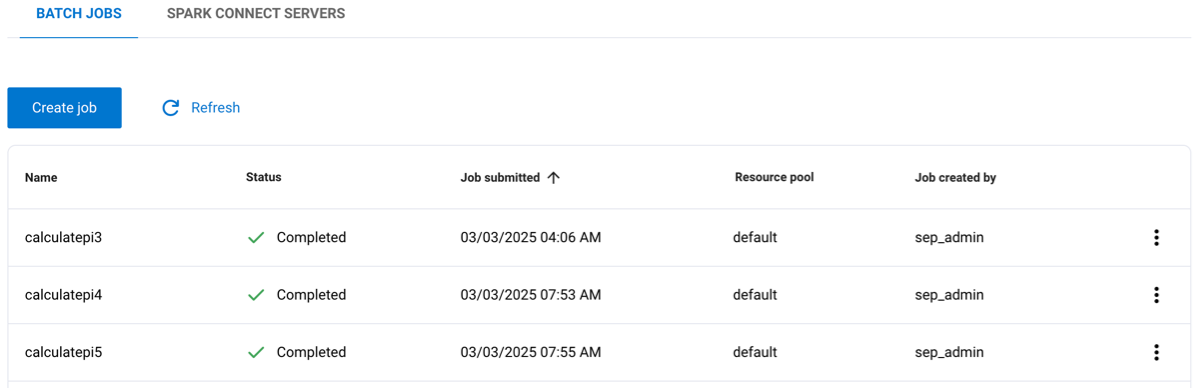
Name: The name given to the job.
Status: The current status of the job, such as completed, running, or pending.
Job submitted: The timestamp for when the job was submitted.
Resource pool: The name of the resource pool assigned to the job.
Job created by: The role that created the job.
Click the Name, Job submitted, or Job created by columns to reorganize the data in ascending or descending order.
The options menu for a Spark job lets you delete the job, download logs, or view the Spark Web UI.
Create batch jobs#
To create a Spark batch job:
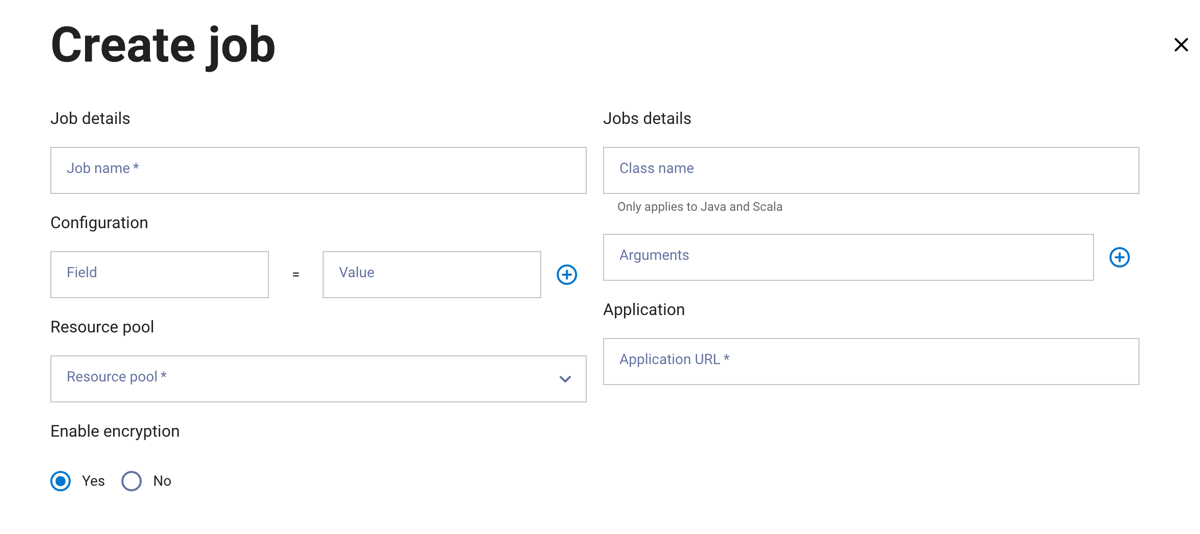
Click Create job.
In the Create job dialog, enter a job name and a class name. The Class name field only applies to Java and Scala configurations and can be left blank if using Python or R. Additionally, arguments can be supplied using the Arguments field.
The Configuration section includes fields to enter properties and their values. Click + to add additional configuration properties.
Select a resource pool to assign to the job.
In the Application section, enter your application’s file path URL.
Choose whether to enable encryption.
Click Next.
Warning
Batch jobs running on a node may fail if the node is rebooted. Automatic failover to another node is not guaranteed.
In the next dialog pane:
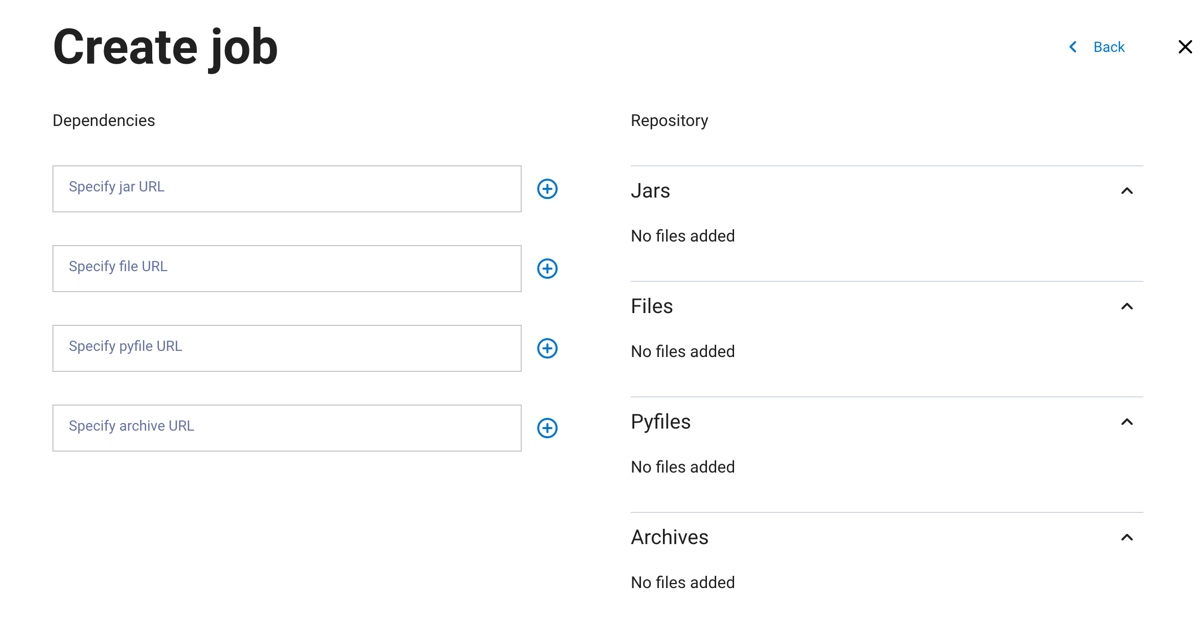
Add the path for your job’s dependencies. Dependencies can be
JAR,FILES,PYFILES, orARCHIVEfiles. Click + to add more dependencies of the same file type. Files are displayed on the right-hand side of the pane.Click Next.
In the next dialog pane:
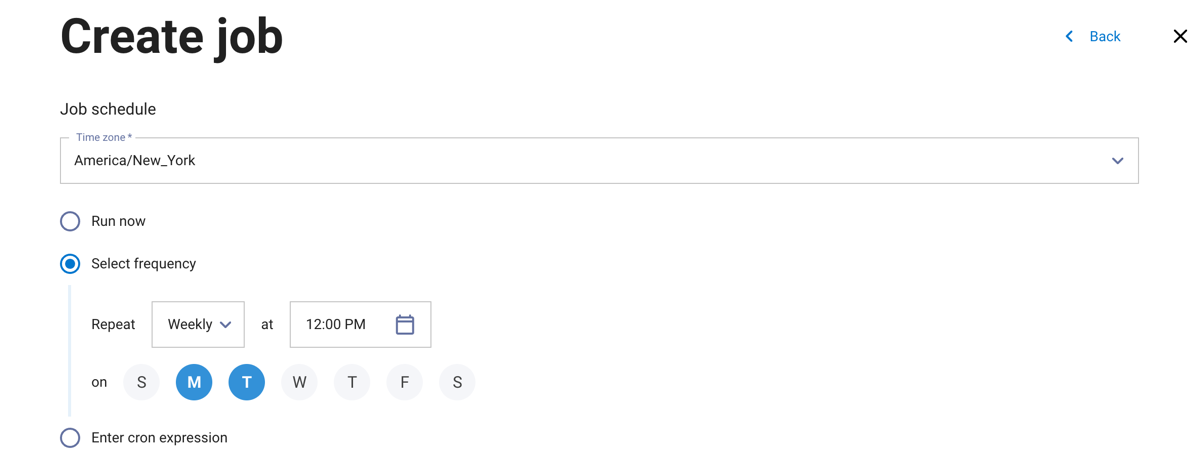
Choose to run the job now or on a recurring schedule. Select a timezone from the drop-down menu, then select a frequency or enter a cron expression to set a schedule for the job to run.
Click Create.
Spark Connect servers#
In the Spark jobs UI pane, click the Spark Connect servers tab to view a list of your existing servers. You must have the Spark runtime UI privilege to access the Spark jobs pane
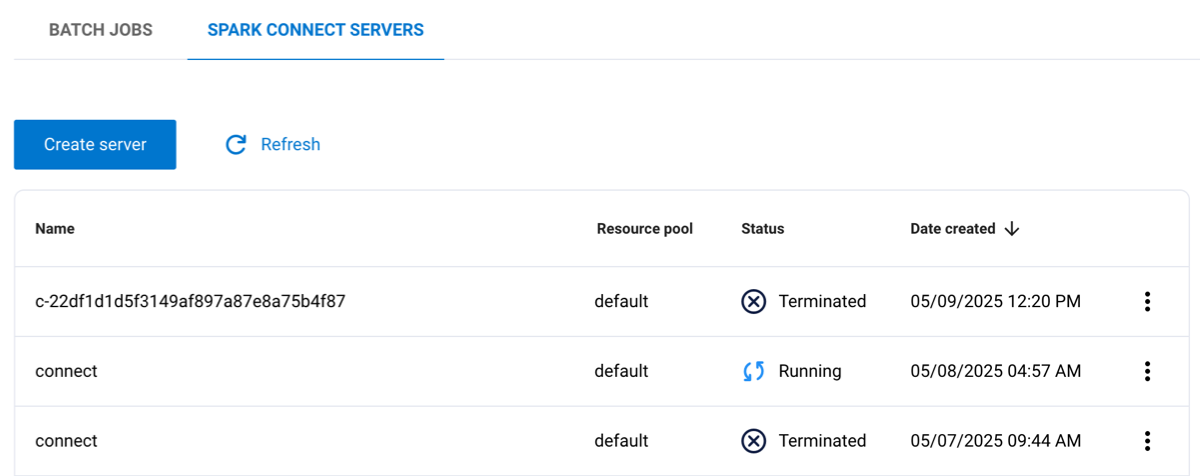
The following columns are listed:
Name: The name given to the server.
Resource pool: The name of the resource pool assigned to the server.
Status: The current status of the server, such as completed or running.
Date created: The timestamp for when the server was created.
Click the options menu for a server to download logs, view the Spark web UI, generate a Spark Connect URL, or delete the server.
Create Spark Connect server#
To create a Spark Connect server:
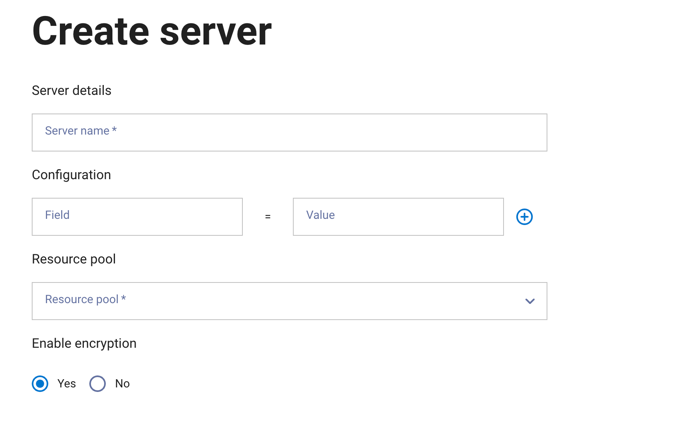
Click Create server.
In the Create server dialog, enter a server name.
The Configuration section includes fields to enter properties and their values. Click + to add additional configuration properties.
Select a resource pool to assign to the server.
Choose whether to enable encryption.
Click Next.
In the next dialog pane:
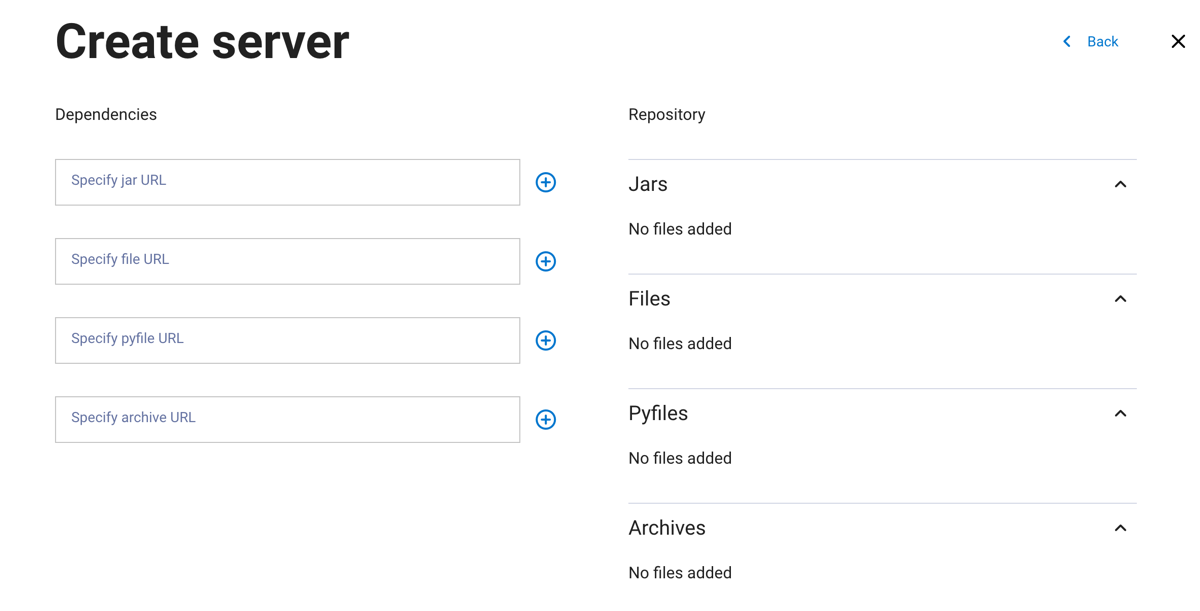
Add the path for your server’s dependencies. Dependencies can be
JAR,FILES,PYFILES, orARCHIVEfiles. Click + to add more dependencies of the same file type. Files are displayed on the right side of the pane.Click Create.
Delete Spark Connect server#
To delete a server, click the options menu for the server and select Delete server.